Monitorización de servidores con Grafana
Introducción
¿Por Qué Monitorizar tus Servidores?
Imagina que tu servidor web comienza a fallar a las 3 AM. ¿Te enterarías antes de que tus usuarios se quejen? La monitorización es tu sistema de alarma temprana que te avisa antes de que los problemas se conviertan en crisis.
Casos reales donde la monitorización salva el día:
- Picos de tráfico inesperados → Escalado automático
- Fugas de memoria → Detección temprana
- Lentitud en la base de datos → Optimización proactiva
- Ataques de seguridad → Respuesta inmediata
Requisitos previos
- Tener acceso a una máquina debian (máquina virtual o física) con permisos de root
- Conocimientos básicos de administración de sistemas Linux
- Conexión a internet para descargar paquetes
- Herramientas necesarias instaladas: wget, curl, net-tools (si no están, instálalas con sudo apt install -y wget curl net-tools).
¿Que es grafana?
Grafana es una plataforma de análisis y visualización de código abierto que se ha convertido en el estándar de la industria para la monitorización. Permite:
- Consultar y visualizar métricas en tiempo real
- Configurar alertas inteligentes
- Explorar logs y trazas
- Crear dashboards interactivos y personalizables
Características principales:
- Soporte para múltiples fuentes de datos (Prometheus, InfluxDB, MySQL, etc.)
- Visualizaciones ricas y personalizables
- Alertas basadas en condiciones complejas
- Comunidad activa con miles de dashboards preconstruidos
Instalación de Grafana en debian
Empezaremos instalando Grafana en nuestro sistema debian haciendo uso del repositorio oficial de grafana, pero antes necesitaremos instalar el software necesario que necesita grafana para poder funcionar ejecutando los siguientes comandos.
sudo apt install -y apt-transport-https
sudo apt install -y software-properties-common wget
El siguiente paso es descargar la llave GPG, para poder firmar los paquetes instalado
sudo wget -q -O /usr/share/keyrings/grafana.key https://apt.grafana.com/gpg.key
Ahora es necesario crear el fichero /etc/apt/sources.list.d/grafana.list para añadir los repositorios de Grafana.
echo "deb [signed-by=/usr/share/keyrings/grafana.key] https://apt.grafana.com stable main" | sudo tee -a /etc/apt/sources.list.d/grafana.list
Actualizamos la lista de paquetes de nuestro sistema
sudo apt update
Una vez actualizado los paquetes del sistema ya podemos empezar a instalar grafana
sudo apt install grafana
Cuando ya tengamos grafana instalado, podremos iniciarlo y añadirlo al arranque de nuestra maquina
sudo systemctl start grafana-server
Para poder asegurarnos de que el servidor se inicia correctamente (debe aparecer con estado active (running)) podemos ejecutar el comando usado anteriormente haciendo uso de la opción “status”.
sudo systemctl status grafana-server
Finalmente habilitamos grafana en el inicio de servidor para que inicie en el arranque
sudo systemctl enable grafana-server.service
Con esto ya estaría completa la instalación de grafana y ya podríamos acceder a la web de grafana para poder logearnos, para ello hay que indicar en la barra de búsqueda de cualquier navegador la ip de nuestra maquina (o su dominio), indicando el puerto 3000 que es el usado por grafana por defecto. en mi caso se accede con la dirección 192.168.110.129:3000
NOTA: por defecto la primera vez que se accede a grafana las credenciales siempre van a ser admin/admin, una vez se acceda por primera vez pedirá un cambio de contraseña y podremos empezar a trabajar con grafana.
Al acceder a grafana, en el menú de la izquierda encontraremos varias opciones interesantes para trabajar como pueden ser los dashboards que podremos configurar para revisar las métricas y monitorizar las maquinas de nuestro sistema, explorar Si su fuente de datos admite datos de gráficos y tablas, Explore muestra los resultados tanto en forma de gráfico como de tabla, alertas que nos permitirá conocer los problemas en sus sistemas momentos después de que ocurren o data sources que proporciona instrucciones paso a paso sobre cómo agregar una fuente de datos de Prometheus, InfluxDB o MS SQL Server.
Instalación de Prometheus
Grafana necesitas añadir un nuevo data source, que es la base de datos que guarda las métricas que muestra Grafana, en este caso se hará uso de prometheus por lo que empezaremos con la instalación de prometheus en nuestra maquina. Prometheus en un sistema open-source de monitorización y alerta.
¿Por Qué Prometheus?
Prometheus es el compañero ideal para Grafana porque:
- Diseñado específicamente para métricas de series temporales
- Lenguaje de consulta potente (PromQL)
- Modelo de datos multidimensional
- Fácil integración con Grafana
Comenzamos instalando prometheus
apt install prometheus prometheus-node-exporter
Tras la instalación de prometheus tenemos que comprobar tanto que tenemos dos conexiones TCP escuchando en los puertos 9090 y 9100, esto lo comprobamos con el siguiente comando
netstat -plunt
Nota: para poder hacer uso del comando netstat tendremos que tener instalado en el sistema el paquete net-tools
Como la version de prometheus que usemos tiene que ser compatible con la de grafana, es recomendable revisar nuestra version de prometheus
prometheus-node-exporter --version
En mi caso la version de prometheus usada es la siguiente
node_exporter, version 1.5.1 (branch: debian/sid, revision: 1.5.0-1)
Configuración de prometheus en grafana
Grafana necesita una base de datos que guarde las métricas guardadas por grafana, en este caso se hará uso de prometheus, otras opciones pueden ser graphite, influxDB u openTSDB entre otros.
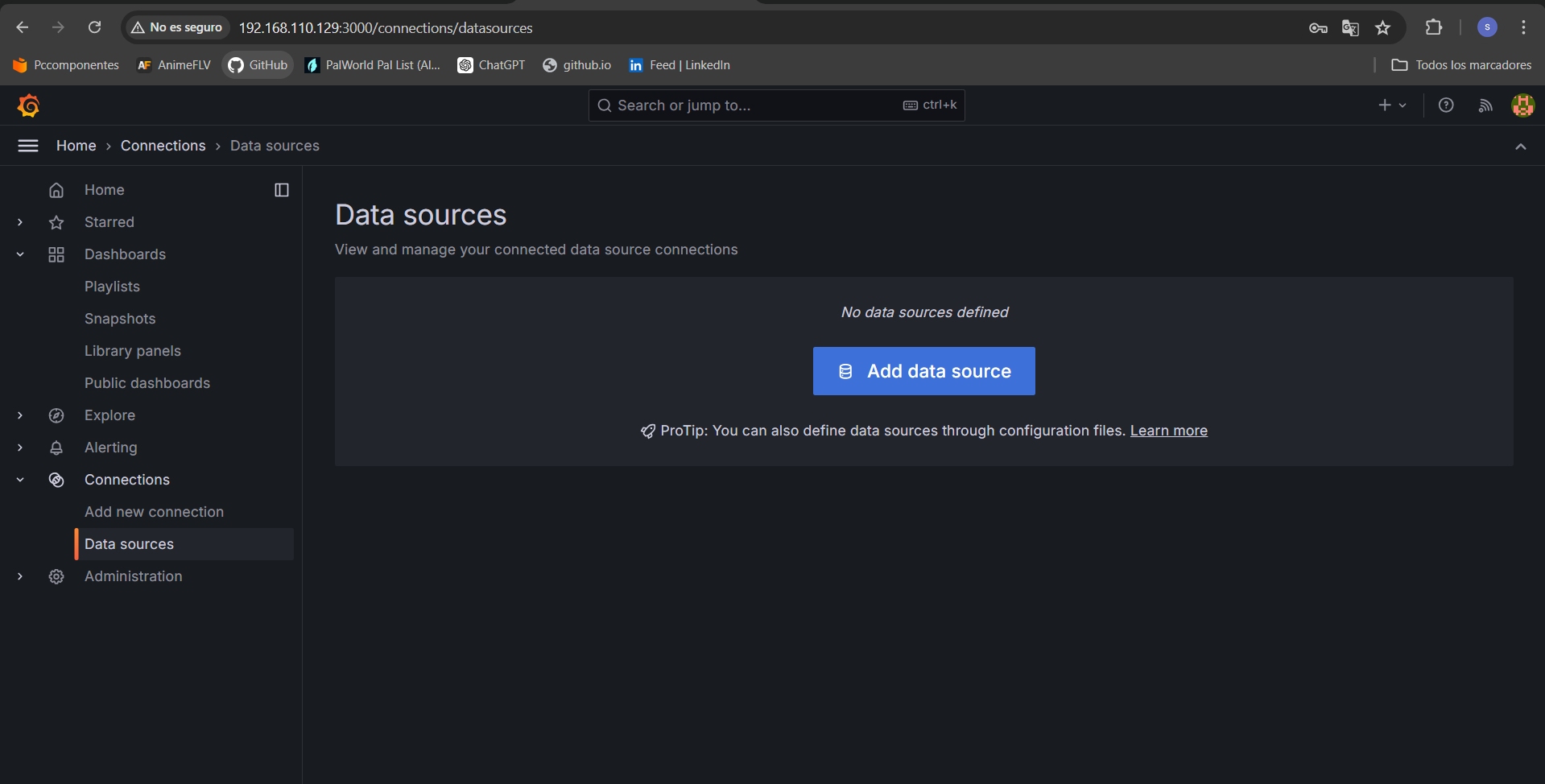
Para añadir la base de datos de prometheus a grafana accedemos primero al sitio web de nuestro grafana como se ha indicado anteriormente, buscando en nuestro navegador la ip o dominio de nuestra maquina e indicando el puerto 3000.
En el menú de la izquierda vamos a la opción “connections” y después a la opción “data sources”, donde nos aparecerá la opción para añadir nuestra base de datos, en este caso prometheus, para ello será necesario añadir la URL http://localhost:9090.
Creación de dashboards
Con grafana tenemos la opción tanto de crear nuestro propio dashboard dependiendo de las necesidades de monitorización que tenga nuestro sistema así como también la opción de importar dashboards creados por la comunidad en Grafana dashboards
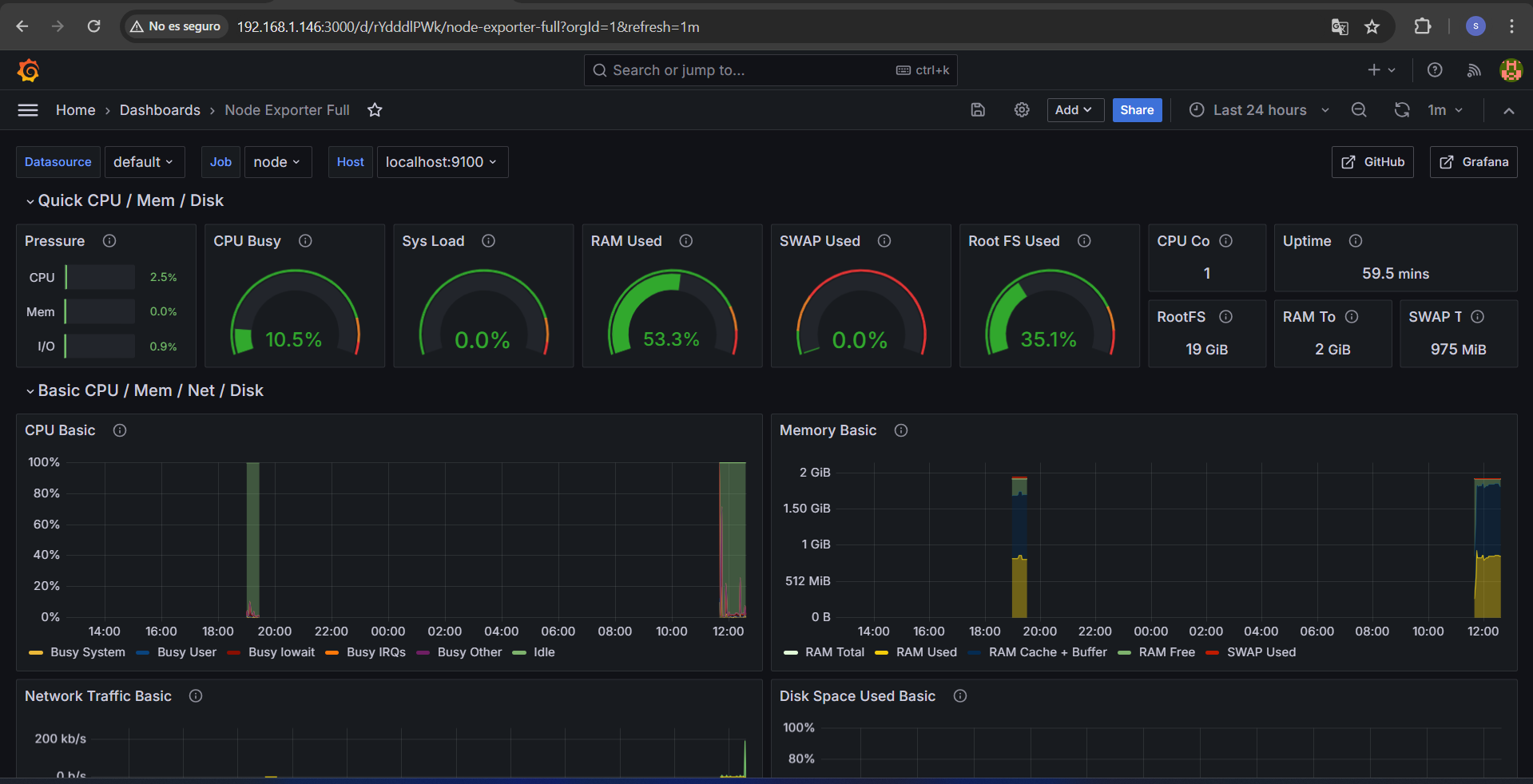
En este caso para importar los dashboards en el menú de la izquierda buscamos la opción de “dashboards”, abrimos la opción “create dashboard” y después entre las tres opciones que nos ofrece grafana seleccionamos la opción “import dashboard”. Una vez ahi para importar el dashboard podemos indicar tanto la url del dashboard como la ID,
A modo de ejemplo se ha usado el dashboard Node exporter siendo el mas descargado por lo que para su uso indicamos la ID de node-exportes (1860) y ya podremos empezar a usar el dashboard.
Si por el contrario en lugar de importar dashboards creados por la comunidad queremos crear nuestros propios dashboards personalizados dependiendo de las necesidades que tengamos a la hora de monitorizar tendríamos que realizar los siguientes pasos:
Al igual que se ha hecho anteriormente, en el menú de la izquierda buscamos la opción de “dashboards” y abrimos la opción “create dashboard” pero esta vez en lugar de seleccionar la opción “import dashboard”, elegimos la opción “+ add visualization”.
Al acceder a “add visualization” lo primero que nos pedirá grafana será que elijamos un data source que será desde donde grafana obtenga los datos de las métricas. Al tratarse de una maquina recién creada en mi caso el único data source que da la opción de seleccionar será el de prometheus pero según las necesidades que tengamos podemos instalar cualquier otro para poder usarlo.
Al crear un dashboard vacío, lo primero que haremos será crear los paneles. Un panel es el bloque básico para la visualización de los datos. Grafana provee diferentes tipos de paneles y cada uno de ellos provee un editor de consulta (query) dependiendo del tipo de Data Source seleccionado.
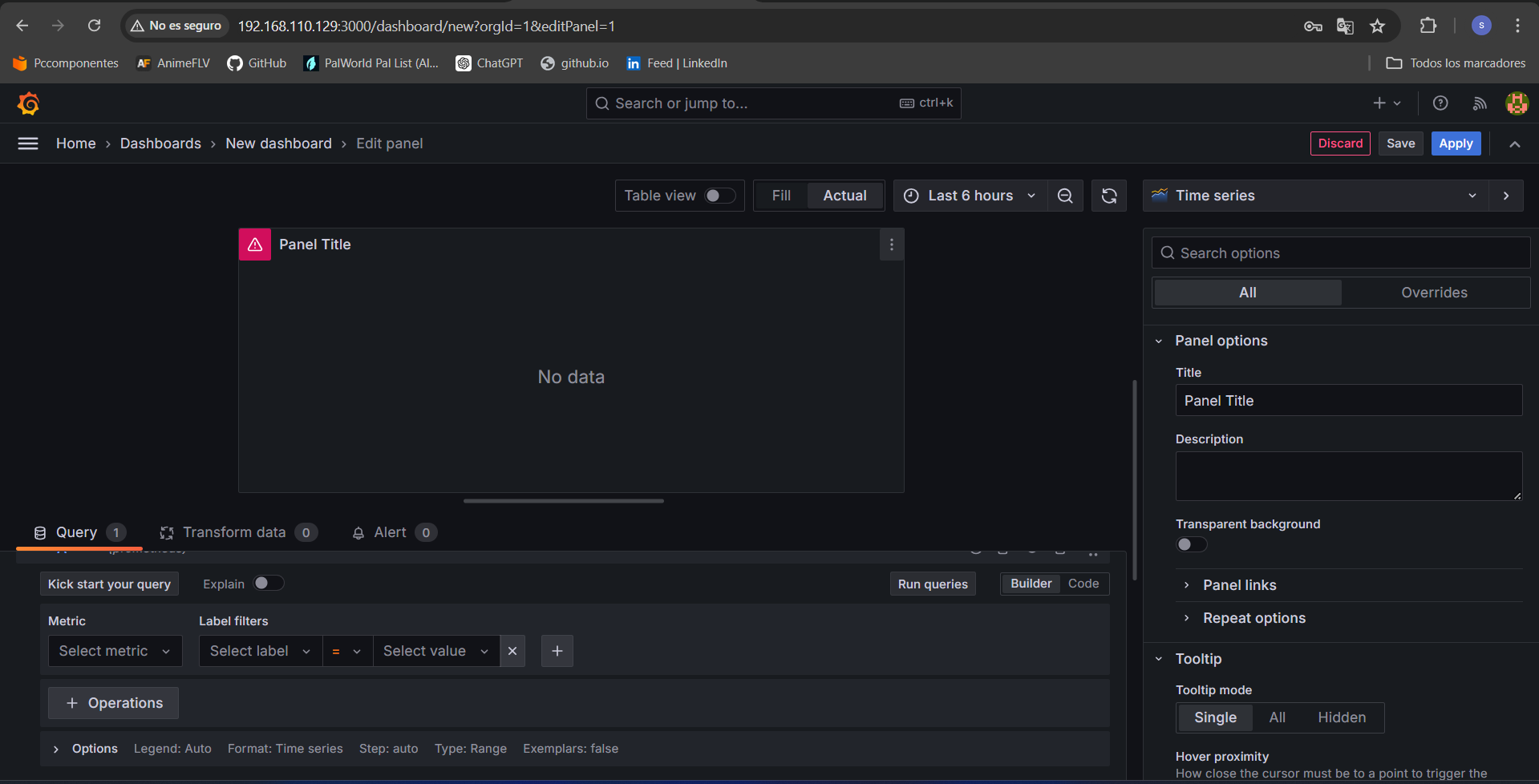
Vamos a crear un panel de tipo gráfico en el que por ejemplo consultaremos la tasa promedio de solicitudes HTTP en los últimos 5 minutos, para ello en la parte de abajo donde visualizamos los paneles encontraremos la opción “query” donde podremos realizar diversas consultas de datos en el apartado “metrics”. Como por ejemplo lo que queremos consultar es la tasa promedio de solicitudes http la métrica que necesitamos seria la de “prometheus_http_request_total”.
También podemos agregar un rango de tiempo para que los datos estén lo mas actualizados posibles, en este caso como rango de tiempo se ha puesto de 5 min, para ello bajo el apartado métrica nos aparecerá una opción llamada “hint: add rate” donde tendremos para elegir distintos rangos de actualización, desde 1 min a 24h.
Cuando tengamos claro el tipo de consulta que haremos, en el apartado derecho seleccionaremos el tipo de gráfica para mostrar los datos ademas de poder seleccionar diversas opciones para que esos datos se muestren lo mejor y mas claramente posible.
La consulta nos quedaria de la siguiente forma:
rate(prometheus_http_request_total[5m])
Configuraciones de paneles
A la hora de configurar y editar nuestros paneles en el menú de la derecha contamos con varias opciones que nos pueden ser útiles para poder diferenciar los datos que mostrara dicho panel en el dashboard. La primera opción que veremos será la que nos permitirá seleccionar la forma gráfica en la que los datos se nos mostraran.
- Panel options
En este apartado podremos ponerle un nombre y descripción (si fuese necesario) al panel que se haya creado. Ademas de indicar un nombre y descripción también contaremos con una opción que puede ser muy util que seria la opción “panel links” lo que nos permitirá compartir paneles entre distintos miembros de un equipo o distintos usuarios compartiendo la url que genere el panel.
Personalización avanzada de dashboards y alertas en grafana
-
Dashboards avanzados Los dashboards en Grafana permiten visualizar métricas de manera clara y personalizada. Para optimizar su uso, puedes aplicar las siguientes técnicas avanzadas:
-
Uso de variables en dashboards Las variables en Grafana permiten cambiar dinámicamente los datos mostrados en los paneles sin modificar las consultas manualmente. Esto es útil cuando deseas filtrar información en tiempo real.
Ejemplo práctico:
Si estás monitoreando múltiples servidores, puedes crear una variable $server con la lista de servidores disponibles. En tu consulta PromQL, en lugar de escribir manualmente cada servidor, usas:
node_cpu_seconds_total{instance="$server"}
Al cambiar la variable $server, los gráficos mostrarán solo los datos de ese servidor.
- ¿Como configurar una variable en grafana?
Para dicha configuracion seguirmos los siguientes pasos:
- Vamos a dashboards settings y seleccionamos la opcion “Variables”.
- Creamos una nueva variable.
- Configuramos la variable.
Usando el ejemplo indicado anteriormente, se configurará la variable $server de la siguiente manera:
* Nombre de la variable: Server
* Tipo: query
* Data source: Prometheus
* Query: label_values(node_cpu_seconds_total, instance)
Indicando label_values(métrica, etiqueta) obtendremos todos los valores únicos de la etiqueta “instance” en la métrica node_cpu_seconds_total. Esto devolverá una lista de servidores registrados en Prometheus, por ejemplo:
server1:9100
server2:9100
server3:9100
- En Multi-value, activamos la opción para permitir seleccionar múltiples servidores.
- En Include All option, marcamos la casilla para agregar la opción All, que mostrará los datos de todos los servidores simultáneamente.
- Guardamos la variable y volvemos al dashboard.
- Filtros y segmentación
Grafana permite filtrar datos en tiempo real sin necesidad de cambiar las consultas directamente en PromQL.
Ejemplo práctico:
Si estás monitoreando diferentes servicios en un clúster, puedes agregar filtros para ver solo las métricas de un servicio en específico, como nginx, mysql, o redis.
- ¿Cómo configurarlo?
-
Añade una variable de tipo Custom con valores como nginx mysql redis. - En la consulta, usamos:
node_network_receive_bytes_total{job="$servicio"}
- Ahora puedes seleccionar el servicio desde un menú desplegable y ver los datos filtrados.
- Uso de templates y dashboards reutilizables
Si necesitas monitorizar múltiples entornos (Producción, Desarrollo, Testing), es recomendable crear dashboards reutilizables en lugar de duplicarlos.
- ¿Cómo hacer un dashboard genérico y reutilizable?
-
Usa variables para definir instancias o entornos ($env = prod dev test). - En las consultas, usa $env en lugar de nombres fijos.
- Guarda el dashboard como Template y reutilízalo en distintas configuraciones.
Configuración avanzada de alertas
Las alertas en Grafana permiten monitorear valores críticos en los sistemas y recibir notificaciones cuando se superan ciertos umbrales.
- Definir condiciones personalizadas
Podemos configurar alertas para detectar problemas antes de que afecten el rendimiento del sistema.
Ejemplo práctico:
Si queremos recibir una alerta cuando el uso de CPU supera el 85% durante más de 5 minutos:
- Vamos a Alerting y creamos la nueva alerta con la opcion “New Alert”.
- Definimos la métrica a monitorear con esta consulta en PromQL:
100 - (avg(rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 85
- Establecemos la condición If above 85 for 5m.
- Configuramos la acción (correo, stack, telegram, etc…). Grafana permite enviar alertas a traves de diferentes plataformas.
- ¿Como configuramos una alerta para slack por ejemplo?
- vamos a “Alerting” y abrimos la opción llamada “notification channels”.
- Creamos un nuevo canal y seleccionamos Slack en este caso.
- Ingresamos la URL del webhook de slack (Un webhook es un mecanismo que permite que una aplicación envíe datos en tiempo real a otra aplicación cuando ocurre un evento específico.).
- Guardamos y asignamos este canal a las alertas configuradas.
- Grupos de alerta para una gestión eficiente
Si se tienen muchas alertas configuradas, es recomendable agruparlas para evitar recibir demasiadas notificaciones.
Ejemplo práctico:
Si monitoreamos múltiples servidores, en lugar de recibir una alerta por cada uno, se pueden agrupar y recibir un solo mensaje que indique cuántos servidores están en estado crítico.
¿Como hacerlo?
Configuramos un Grupo de alertas en Grafana.##
Paso 1: Crear primer grupo - alertas CPU
- Inicia sesión en Grafana (http://tu-servidor:3000)
- Haz clic en el icono de campana en el menú lateral
- Selecciona “Alerting” → “Alert rules”
Paso 2: Crear un Nuevo Grupo de Alertas
- Haz clic en “New alert rule”
- Pestaña “Set alert rule name” y aadimos la informacion basica:
# Ejemplo para grupo CPU
Rule name: "HighCPUUsage-Critical"
Group: "cpu-alerts" # ← Este es el nombre del grupo
Paso 3: Configurar la Consulta de la Alerta
- En la pestaña “Define query and alert condition” Seleccionamos como Data Source: Prometheus
- Configuramos la consulta:
# Para alerta crítica de CPU
100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 90
Paso 4: Configurar Etiquetas (Labels)
- En la pestaña “Add Details”:
Labels:
- severity: critical
- resource_type: cpu
- team: infrastructure
- priority: p0
Apartado annotations:
summary: "CPU crítico en "
description: "Uso de CPU en % por más de 3 minutos"
dashboard: "/d/node-exporter-full"
Paso 5: Por ultimo seleccionamos la opcion save rules
Ademas de poder configurar los grupos de alertas a traves del entorno grafico de Grafana, tambien es posible gestionar los grupos de alertas a traves de ficheros.yml. Estas alertas se configurarian en /etcgrafana con la siguiente estructura:
Configuración a traves de archivo .YML
Estructura de ficheros
/etc/grafana/
└── provisioning/
└── alerting/
├── config.yml # Configuración principal
├── alertmanager.yml # Configuración Alertmanager
└── rules/
├── cpu-alerts.yml
├── memory-alerts.yml
├── disk-alerts.yml
└── service-alerts.yml
Configuracion principal del fichero config.yml:
apiVersion: 1
alerting:
- name: Alertmanager
type: alertmanager
access: proxy
org_id: 1
url: http://localhost:9093
editable: true
alerting_rules:
- name: Infrastructure Alerts
org_id: 1
interval: 1m
rules:
- group: cpu-alerts
rules_path: /etc/grafana/provisioning/alerting/rules/cpu-alerts.yml
- group: memory-alerts
rules_path: /etc/grafana/provisioning/alerting/rules/memory-alerts.yml
- group: disk-alerts
rules_path: /etc/grafana/provisioning/alerting/rules/disk-alerts.yml
Explicacion del fichero de configuracion
-
Api version: 1 (este valor no es necesario cambiarlo). Este parametro define la versión del esquema de configuración. En las versiones actuales de grafana este valor siempre tiene que ser 1.
-
Alerting - configurador de alertmanager: Configura cómo Grafana se conecta con Alertmanager para gestionar y enviar notificaciones. En el bloque alerting tenemos varios parametros:
- name: Identificador unico para la configuracion de alertmanager. Este parametro puede repetirse si se tienen varios alertsmanager.
- type: Especifica el tipo de recurso que se está configurando, Siempre tiene que tener valor alertmanager.
- access: Define como grafana accede a alertmanager. Suele tener dos valores, Proxy cuando Grafana actua como intermediario o Direct si el navegador se conecta directamente.
- org_id: 1: Identifica la organizacion de Grafana. El valor por defecto suele ser 1, haciendo referencia a la organizacion principal, en caso de hacer referencia a una organizacion segundaria, se cambiaria el valor a 2.
- url: Indica donde esta ejecutandose alertmanager.
- editable: Permite cambiar o no la informacion desde el entorno grafico de grafana, dependiendo de si se pone a True o en False.
- interval: Frecuencia de evaluacion de alertas.
- rules: Donde se definen los grupos.
- rules_path: Ruta absoluta al archivo .yml con las reglas.
Configuracion de fichero cpu-alerts.yml:
groups:
- name: cpu-alerts
interval: 1m
rules:
- alert: HighCPUUsageCritical
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 90
for: 3m
labels:
severity: critical
resource_type: cpu
team: infrastructure
priority: p0
annotations:
summary: "CPU crítico en "
description: "Uso de CPU en % por más de 3 minutos"
dashboard: "/d/node-exporter-full"
- alert: HighCPUUsageWarning
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[2m])) * 100) > 80
for: 5m
labels:
severity: warning
resource_type: cpu
team: infrastructure
priority: p1
annotations:
summary: "CPU alto en "
description: "Uso de CPU en % por más de 5 minutos"
Para que estas configuraciones se apliquen correctamente tendremos que reiniciar grafana primero.
sudo systemctl restart grafana-server
Una vez reiniciado el servicio ya deberiamos tener configurados los grupos de alertas.